What Is Deep Learning?

Starting in 2017, Aiera has quickly become a trusted virtual analyst for many stock investors and asset managers. Aiera is not a successful businessperson who works remotely. It is an event intelligence and insights platform, and its name is an acronym for artificially intelligent equity-research analyst.
The Aiera platform consolidates and processes data from multiple sources, such as live events, news articles, and social-media feeds. It also prepares monitoring dashboards and presents insights based on the processed data.
What has enabled Aiera to scour vast amounts of data and make accurate assessments about the data? Deep learning.
Here Technologies is another company that relies on deep learning. It uses deep learning to generate mapping and navigation data for various sectors, including the autonomous-vehicle sector.
There is also Neurala, a company that uses deep learning to simulate humanlike visual powers in machines. Its vision artificial intelligence, or vision AI, software can automate the visual inspection and quality control of assembly-line products, thereby helping manufacturers save time and money.
Alexa Conversations (beta) is another manifestation of the power of deep learning. It is a deep-learning-based approach to making conversations between Amazon Alexa and its users more natural and humanlike.
With computer hardware and processing speeds improving at a fast pace and the demand for automation escalating, deep learning has many takers today. It is also likely that deep learning will remain a force to reckon with for many years in the future, until we discover a better alternative.
In this article, we will understand what deep learning is. This article is part of the Mastering Deep Learning Through Projects series of articles. It is a precursor to the subsequent project-based articles in the series and is meant to establish your expectations from the series.
Article Objectives
After completing this article, you should be able to
- describe deep learning.
- distinguish deep learning from plain machine learning.
- list a few applications of deep learning.
Let us begin with a description of deep learning.
Describing Deep Learning
Deep learning is the science of automatically obtaining new insights and interpretations from data. Deep learning is a subset of machine learning.
In machine learning, and so in deep learning as well, we use specialized algorithms1 to convert sample data into meaningful models. These models are also known as machine-learning models.
The following figure summarizes how we create machine-learning models:
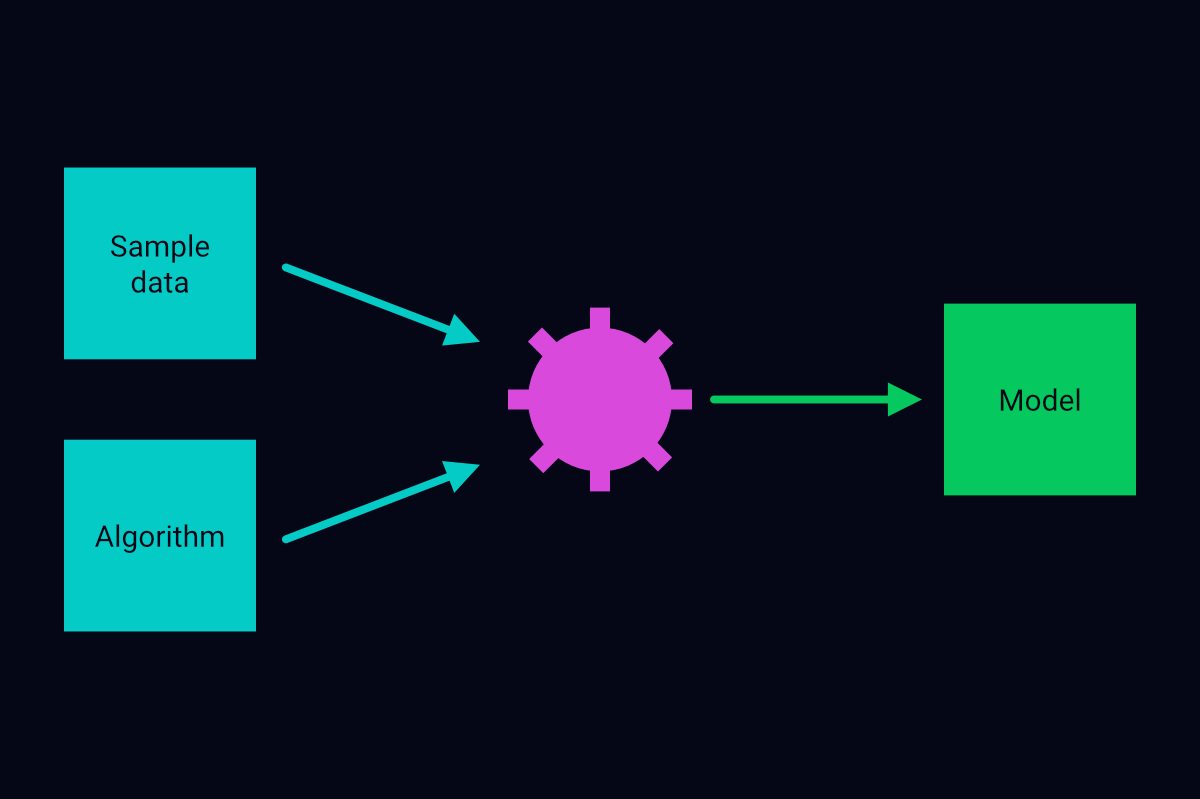
The process of building a machine-learning model
The Model-Building Process
We can divide the model-building process into the following steps:
- Determine the type of machine-learning problem: supervised, unsupervised, or reinforcement.
- Obtain sample data.
- Select a machine-learning algorithm.
- Instantiate a machine-learning model based on the algorithm.
- Train the model on the sample data.
During training, a model learns the rules that interrelate the variables in its sample data.
We will discuss model-building steps in detail in subsequent articles, where we will work on projects. For now, let us outline a few important aspects of sample data and models.
We will first discuss the categories into which sample datasets are subdivided. Next, we will discuss how data is grouped within a sample dataset. Then, we will find out how machine-learning models use sample datasets.
The Categories of Sample Data
Both plain machine learning and deep learning let us use diverse sources of sample data. We can group these sources into two categories, structured and unstructured.
Structured data
Structured data is tabular. Its examples include data stored in comma-separated-values (CSV) and Microsoft Excel files.
Unstructured data
Emails, presentations, PDF documents, images, and audio and video files are examples of unstructured data. These data sources don’t have any specific format or organization. Deep learning is best suited for deriving insights from unstructured data.
Next, let us understand how a sample dataset is organized.
The Components of a Sample Dataset
Sample data of a specific category—structured or unstructured—also has subdivisions. These subdivisions are called variables and are of two types, independent and dependent.
Independent Variables
The independent variables of a dataset represent the inputs that generate the desired output. A sample dataset contains one or more independent variables.
Suppose we want to build a model that can predict whether or not the salary of a person is greater than USD 50,000. In this case, the independent variables could be the education levels, job types, ages, ethnicities, and years of work experience of various types of people.
If we want to predict video sales, the independent variables could include features of video games. A few examples of these features are genre, publisher, and platform.
Dependent Variables
A dependent variable represents the output that each set of independent variables of a sample dataset generates. Dependent variables are also known as target variables. We want a machine-learning model to finally predict dependent values, given unseen2 sets of independent values.
The dependent variable of a salary classifier could indicate the salary ranges of individuals. In the case of a product-sales predictor, the dependent variable could constitute the sales in millions of various products.
Suppose the independent variable in a dataset consists of unstructured data, such as images. In this case, the labels of those data elements would comprise the dependent variable.
We use datasets that have clearly identified dependent variables for supervised machine learning.
A dataset that does not specify a dependent variable is suitable for unsupervised machine learning.
Customer segmentation is an unsupervised learning problem. The sample data for this problem contains details about the customers of a company. We use unsupervised learning to categorize the customers into segments.
A dataset of unstructured data can also be devoid of a dependent variable. In this case, we would use unsupervised learning to find interrelations among the elements of the dataset.
Now that we know the categories and components of sample data, let find out how machine-learning models use sample datasets.
Understanding the Basic Functions of a Machine-Learning Model
A machine-learning model obtains the following answers from its sample data:
How are the independent variables interrelated?
How do the independent variables generate their corresponding dependent variable, if any? For example, how do weather conditions and the hour of the day affect the demand for bike rentals?
The rules that interrelate the variables are the answers. The model identifies these rules on its own when we train it on its sample data.
We don’t have to program any logic to help a model identify rules. The model uses its foundational algorithm as a blueprint for rule identification.
If we supply a trained model with unseen data, the model will either
generate a corresponding dependent variable or
tell us how the input values should be grouped or interrelated.
The output of the trained model depends on whether the sample data contained a dependent variable or not.
Any unseen data that we supply to a model must have the same structure as the sample data on which we had trained the model.
Machine-learning models are a fascinating concept overall. But what has made deep-learning models even more popular than plain machine-learning models? Let us find out.
Distinguishing Deep Learning from Plain Machine Learning
A plain machine-learning model tries to learn from all the features that are available in its sample data at once. In addition, we have to intervene to ensure that the sample data that we supply to the model contains the right features in the right format.
We have to combine the features of the sample data, remove some features, standardize the features that remain, and even change their formats—for example, convert nominal features into numerical features. If we don’t do so, a plain machine-learning model will give inaccurate results.
We don’t have to make so much effort if we use a deep-learning model. This type of model learns features progressively, across multiple layers. And it learns on its own. We don’t need to manipulate features to a great extent to make them conducive to deep learning.
That’s why deep learning is so efficient with unstructured data, such as images. We cannot identify or modify the features of an image at a granular level, but a deep-learning algorithm can. This makes deep learning fast and accurate.
Deep learning uses a strategy similar to the human brain’s to learn information. The brain learns through an interconnected network of neurons. In a similar fashion, a deep-learning model learns via a hierarchical network of layers.
The layer hierarchy of a deep-learning model is also called an artificial neural network.
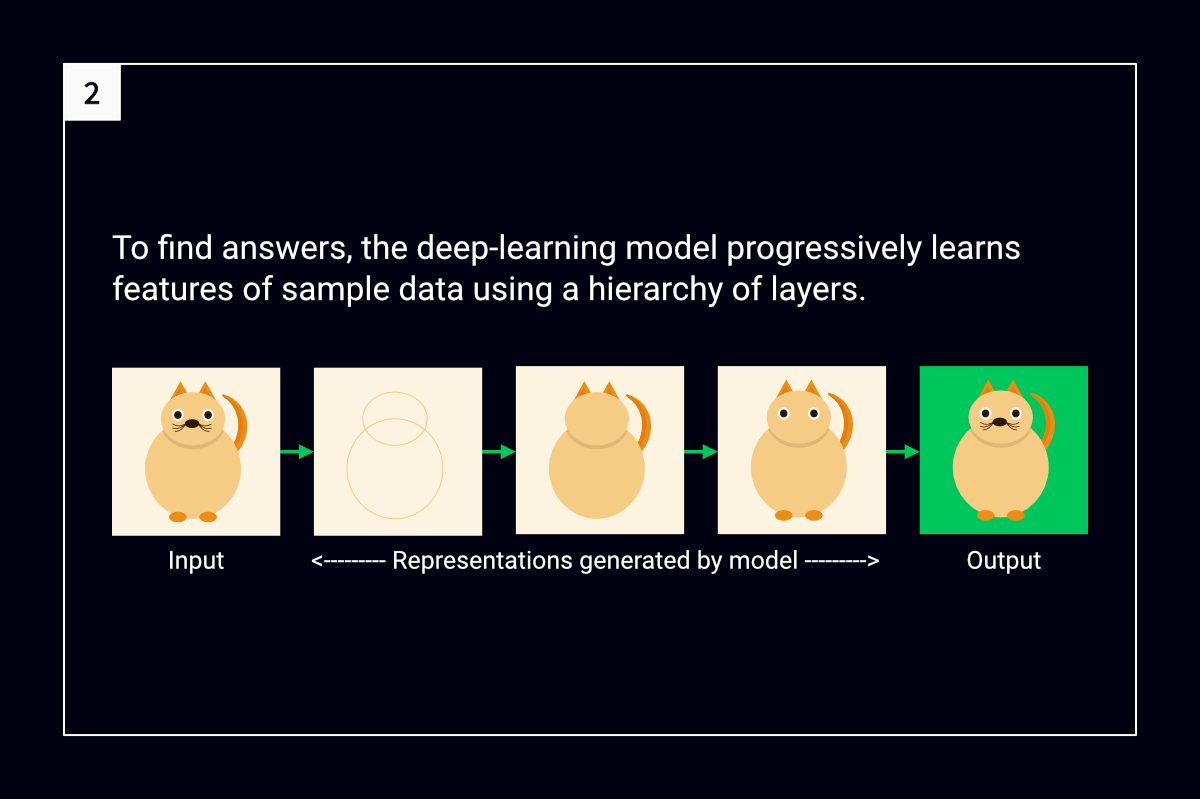
The following figures summarize how deep learning interprets an image:

The gist of deep learning
Layered, hierarchical learning
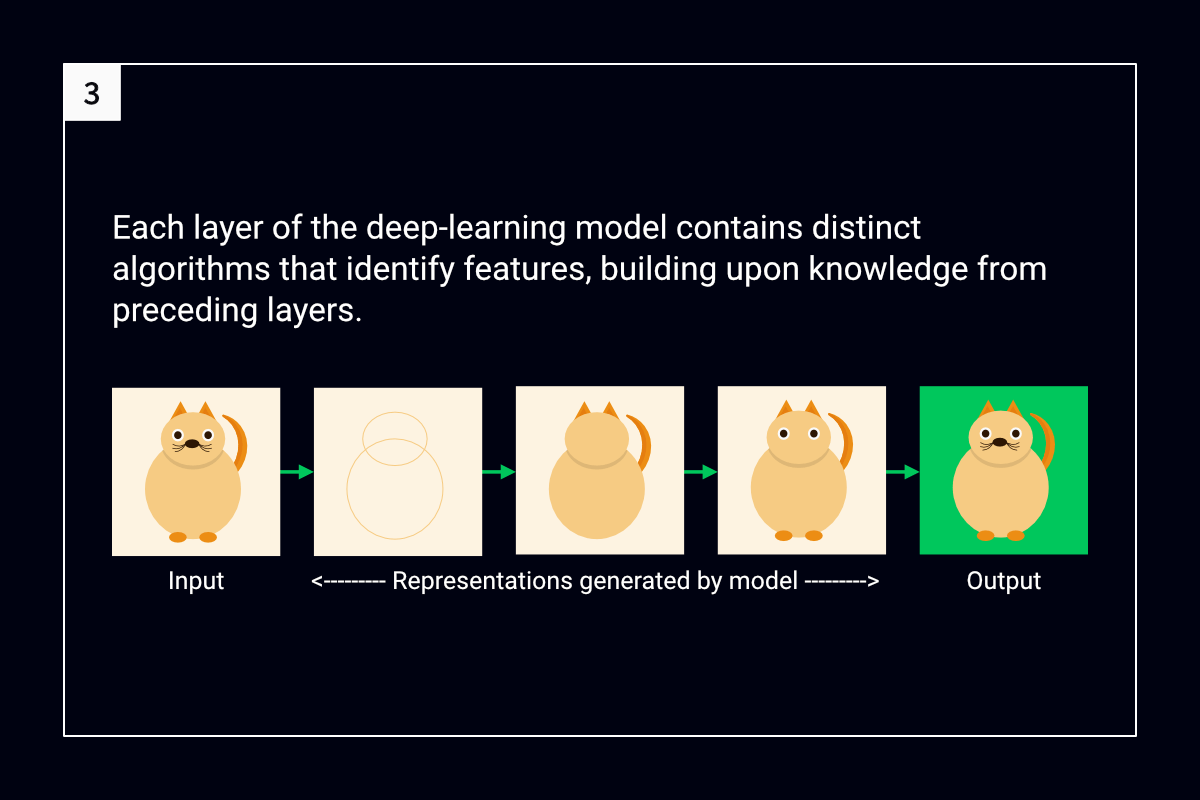
Distinct algorithms per layer
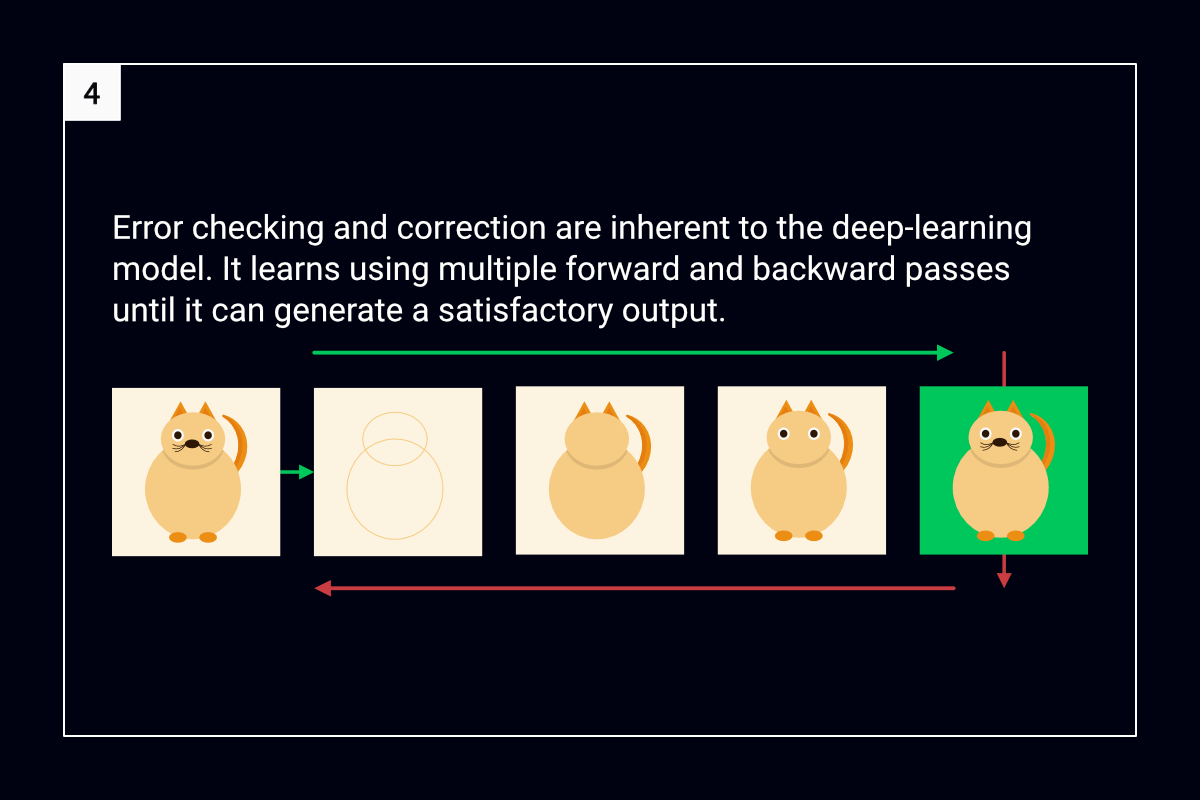
Multiple passes with integrated error correction
A typical deep-learning model contains three or more layers, and each of its layers comprises one or more algorithms. The initial layer of the model learns as many features as its algorithms can and generates a representation of the source data. Then, it passes on the representation, as well as details about the features that it has learned, to the second layer.
The second layer does the same, passing on a data representation and feature details to its succeeding layer. This process continues until the final layer, which outputs a final data representation.
Error identification and correction are part of the standard deep-learning process. This is contrary to how plain machine-learning models work. We have to intervene to identify errors made by plain machine-learning models and make adjustments to fix or reduce the magnitudes of those errors. A deep-learning model identifies and fixes errors automatically.
Let us find out more about how a deep-learning model implements error identification and correction.
Explaining Error Handling in Deep Learning
Consider a deep-learning model that is meant to distinguish between photos of cats and dogs. While learning to identify photos, the model performs multiple forward and backward passes across its layers until it can achieve a satisfactory degree of accuracy. The aim of the model is to reduce the number of incorrect identifications.
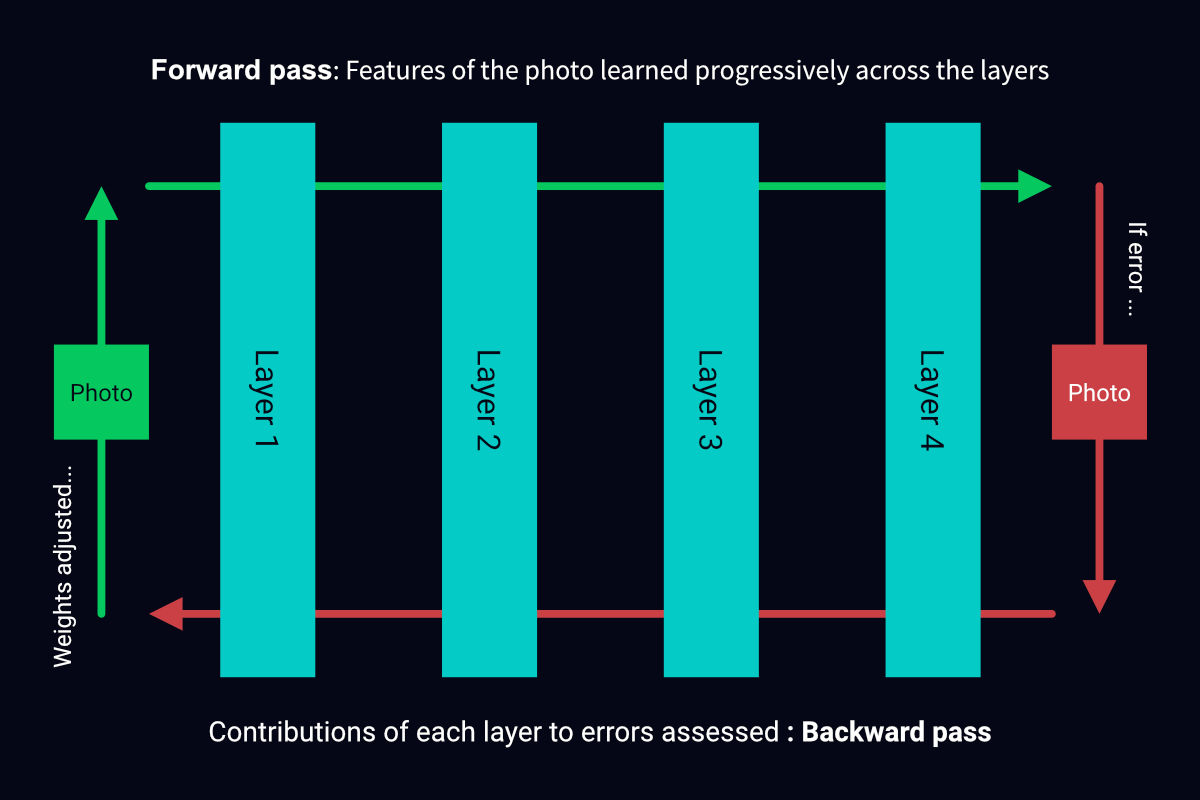
During a forward pass, the model learns the most basic features of a photo at its first data layer. Then, it progressively builds upon the features in subsequent layers until it can form a complete picture.
Next, the model compares the picture that it has formed with the actual picture. In other words, it assesses the output error—the difference between the desired and actual results.
If the output error exceeds a predefined threshold, the model performs a backward pass. During a backward pass, the model assesses how much each layer contributed to the output error, starting with the last layer and moving backward.
A forward pass follows the backward pass. During this forward pass, the model tries to minimize the output error. Primarily, it adjusts the weights that each layer had assigned to features of the photo. The adjustments depend on the assessments that the model had made during the backward pass.
The cycle of forward and backward passes continues until the output error falls below the predefined threshold.
The following figure summarizes the error checking and correction process:
Error checking and correction in deep learning
Deep learning seems suitable for image classifications. In which other areas can we use it?
The Applications of Deep Learning
Deep learning is ideal for machine-learning tasks that require high computational power and involve large amounts of source data. Aside from image classification, some of the other applications of deep learning are speech recognition, text-to-speech conversion, and language translation.
Now that we have a fair idea of what deep learning is, we can move on to the first project. But before we do so, let us summarize what we discussed in this article.
Conclusion
Deep learning is a subset of machine learning. Like plain machine learning, deep learning lets you use specialized algorithms and source data to build models. These models, once trained, can generate insights from new data.
Deep learning is much faster than plain machine learning, and it works very well with unstructured data, such as emails, images, and videos. This is because, at a superficial level, a deep-learning model functions like the neural network of the human brain to enhance its learning.
Just as the human brain learns via an interconnected network of neurons, a deep-learning model learns by using a hierarchical network of layers. It is this hierarchy that gives a sense of depth to deep-learning models.
A deep-learning model can learn features and their interrelations by itself, without human intervention. In addition, because the model learns progressively across layers, its outputs tend to be highly accurate.
What adds to the appeal of deep learning is that, unlike plain machine learning, it does not require human intervention to identify and fix errors. Its models do so automatically as they perform multiple backward and forward passes across their layers.
Deep learning is not an esoteric art. You can grasp the concepts of deep learning through practice. So, take a break and then begin your first project.
References
Machine-learning and deep-learning books from the following publishers: