What Is Machine Learning?

Gmail uses machine learning to transfer spam messages to your Spam folder without your intervention. Citibank uses machine learning to identify fraudulent transactions. Various other companies also use machine learning for tasks such as price prediction, customer classification, and product categorization.
Machine learning is not a buzzword. It is a set of techniques that have many practical applications today.
In this article, we will get acquainted with the foundational aspects of machine learning.
Article Objectives
After reading this article, you should be able to
- describe machine learning.
- explain the process of implementing machine learning.
- distinguish between various types of machine learning.
- compare traditional computing with machine learning.
- identify the prerequisites for grasping machine learning through this website.
Let us begin with a description of machine learning.
Describing Machine Learning
Machine learning is the science of building applications that can generate outputs automatically. You don’t hard code decision-making logic into these applications. Instead, you incorporate machine-learning models into them.
Let us find out how we can use models to implement machine learning.
Implementing Machine Learning by Using Models
To build a basic machine-learning model, we need sample data and a specialized blueprint, which is also known as a machine-learning algorithm1. We initialize the model as an instance of the algorithm. Then, we configure the model to learn the rules that interrelate variables in the sample data. This process is known as model training.
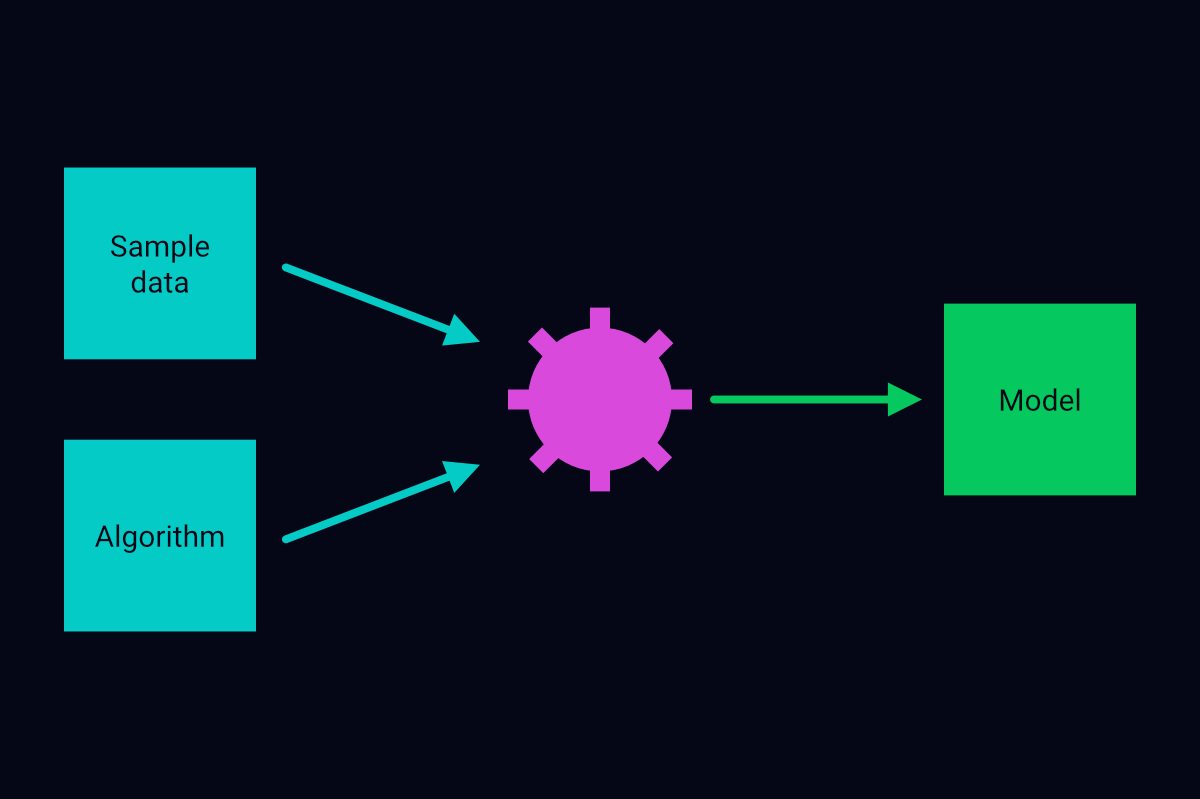
The process of training a machine-learning model
A trained model can apply the rules that it has learned to new data and make predictions. Its only constraint is that the new data should have the same structure as the sample data.
We generally train a machine-learning model in multiple passes and even build multiple models using different algorithms for the same project. Our goal is to obtain a model that generates reasonably accurate outputs. Once we have this model, we configure an application, such as a web page or a mobile app, to use the model in a production environment.
But that’s not all. We keep improving and retraining the model using up-to-date data even after we have deployed it.
Let us understand the model-building process further using an example.
An Outline of the Model-Building Process
Suppose you want to use machine learning to predict the demand for bike rentals during any given hour of a day. To achieve this objective, you will first perform the following broad-level steps to build a model:
Determine the type of machine-learning problem—for example, supervised, unsupervised, or reinforcement. You can consider demand prediction a supervised-learning problem.
Obtain sample data that contains independent and dependent variables. The independent variables should include weather details about each hour of each day for the past several years. The dependent variable should comprise the demand for bikes during each of those hours.
Select a machine-learning algorithm.
Instantiate a machine-learning model based on the algorithm.
Train the model.
During training, a model learns the rules that interrelate the variables in its sample data.
Once you have trained the model, you can test it by supplying it with independent variables2 related to an hour of a specific day. You should be aware of the actual rental demand during that hour so that you can validate the value that the model predicts. Depending on how accurate the model is, it will return a value that is close to or much less or higher than the actual demand.
Next, you could try to retrain the model to improve its performance. You could also build new models using other algorithms. Once you are satisfied with the prediction accuracy of the original model or any one of the alternative models, you could deploy the model as an application programming interface (API). You could also set up a front-end application to consume the API. The application would include a form that lets users pass on independent variables for a give hour to the API and obtain an estimated rental demand for that hour.
We will discuss model building in detail in subsequent articles, where we will work on projects. In this article, we will learn about machine-learning types next.
Types of Machine Learning
Machine learning is four types: supervised, unsupervised, semi-supervised, and reinforcement.
Let us first discuss what supervised learning is.
Supervised Learning
In supervised learning, the sample data of a model contains one or more independent variables and their corresponding output or target variable. If you are using a tabular dataset, the columns of the dataset would represent the variables. If you are using unstructured data, such as a set of images, videos, or PDF documents, features such as colors, shapes, and topics might be the independent variables and any labels, such as the type of a photo or the category of a video or document, could constitute the target variable.
A supervised-learning model uses its algorithmic blueprint to learn how independent variables generate their corresponding output. If you supply a trained supervised-learning model with new independent variables (unseen data3), it automatically predicts the output of the variables. The model uses the rules that it learned from its sample data to do so.
Supervised learning is of the following types:
Classification: In classification, the target variable consists of two or more classes (binary or multi-class classification). Predicting whether a credit-card customer will default on payment, given details such as the customers’ salary, education level, and employment type, is a classification problem. Other examples of the classification problem are predicting employee attrition—“Will Jonah leave or stay?"—identifying handwritten digits in photos, and determining the class to which a seed of wheat belongs.
Regression: A regression problem is about predicting a numerical value. Determining the salaries of individuals based on their education, age groups, and locations is a regression problem. Predicting the prices of specific products, the total number of units of a product that will be sold, and the number of likes that a social-media post will receive are also regression problems.
Next, let us look at unsupervised learning.
Unsupervised Learning
In unsupervised learning, the sample data does not contain any explicitly defined target variable. The assigned machine-learning model learns how to organize the sample data on its own and returns reasonable interpretations based on the data.
Unsupervised learning is of the following types:
Clustering: A clustering model classifies the sample data into groups based on similarities and dissimilarities among the elements of the data. Creating customer segments as per factors such as customers’ ages, past product preferences, spending capacity, and preferred time of shopping is an example of clustering. Another example is evaluating access requests to a social-media website to identify anomalous requests. As the requests are not classified beforehand, this is an unsupervised-learning problem that we can solve through clustering.
Association: An association model looks for links among elements of its sample data. For example, in a dataset about product purchases, it determines whether the purchase of one product, say a drawing board, leads to the purchase of two related products—drawing paper and crayons.
Dimensionality reduction: We use dimensionality reduction to reduce the number of features or variables in a data sample while retaining all relevant information. If the data sample is in tabular format, we could combine some of its columns to reduce dimensionality. If it contains two-dimensional images, we could compress each image into one dimension.
We will learn about semi-supervised learning next.
Semi-Supervised Learning
Semi-supervised learning is a combination of supervised and unsupervised learning. The sample data of a semi-supervised model specifies only a few target categories. The model identifies all the other categories on its own.
A common application of semi-supervised learning is in the classification of a large number of photos. Only a few of the photos in the sample data of this type of project are grouped into classes. The project model classifies all the other photos itself.
Finally, let us discuss reinforcement learning.
Reinforcement Learning
Reinforcement learning is about configuring applications that learn from any positive and negative responses that they receive from their environments. The applications consider positive responses as rewards and the actions that triggered those responses as suitable. They repeat these actions in the future. Negative responses are penalties for them, and they try to avoid or mitigate the effects of the actions that triggered those penalties.
For example, a robot can use a reinforcement-learning model to walk in a busy area, avoiding impediments when they appear in its path. To ensure that the robot automatically avoids impediments, the model would learn from historical and realtime data about various steps in the walking process and whether those steps are positive or negative.
So, each type of machine learning, whether supervised, unsupervised, semi-supervised, or reinforcement, provides us a way to solve a real-world problem. Does this mean it is time to give up traditional computing? Should we adopt machine-learning for all purposes?
No, traditional computing also has its use cases.
Let us determine the scenarios where traditional computing is a better fit and the scenarios where machine learning is ideal.
Comparing traditional computing with machine learning
A traditional computer application uses hard-coded, logical steps, also know as traditional algorithms, to accomplish tasks. A traditional algorithm accepts an input, processes it, and returns an output.
An algorithm that accepts three numbers and returns the sum of their squares using a blueprint of sequential instructions is a traditional algorithm. If the inputs to the algorithm are \(x\), \(y\), and \(z\), its blueprint specifies the steps to calculate an output using the formula \(x^2 + y^2 + z^2\).
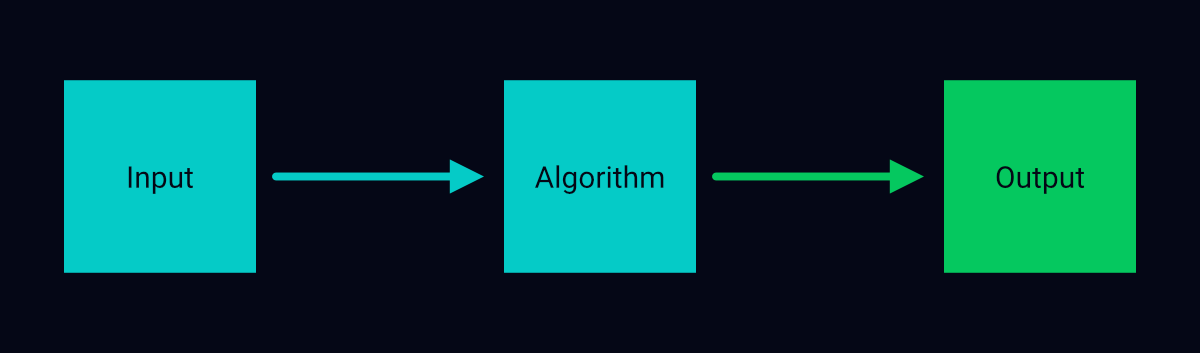
The working of a traditional algorithm
A traditional algorithm is best suited for problems that we can solve using straightforward formulas and data whose elements have simple interrelations. If the input data is multifaceted and its elements have complex interrelations, use machine-learning algorithms instead. Writing traditional algorithms for such scenarios can be tedious and time consuming.
Typically, you will want to avoid using traditional algorithms to implement functionalities such as the following:
Teaching a robot to walk in a busy area
Teaching a robot to hold an intelligible conversation
Configuring an irrigation system to not water plants when it is raining heavily
Setting a self-driving car to brake when an object is a few feet ahead and there is a chance of a collision
Predicting the demand for bike rentals during an hour based on factors such as humidity, temperature, wind velocity, season, time of the day, and day of the week.
These functionalities require complex and multifaceted data. It is easier to use preconfigured machine-learning algorithms to derive interpretations from such data.
The scikit-learn library provides an assortment of machine-learning algorithms that you can readily use to implement some of these functionalities. To implement the others—teaching a robot and configuring a self-driving car—you can use deep-learning libraries such as TensorFlow and PyTorch.
How can you become adept at using scikit-learn algorithms? Let us find out.
Mastering the Use of Scikit-Learn Algorithms
To learn to use scikit-learn algorithms in the real world, follow the plain machine-learning articles on this website. Instead of focusing on theory, which you can quickly forget, the articles focus on practical code that gives immediate, measurable results. You will assemble the code for each project in a step-by-step manner, grasping any theoretical aspects as and when you need to apply them.
Next, let us discuss what you will need to complete the machine-learning projects on this website.
Identifying the Prerequisites for Scikit-Learn Projects
To be able to work through projects that are centered around scikit-learn, you should
- understand Python syntax.
- be able to write simple programs in Python.
- understand the relevance of modules and libraries in Python programs.
- own a Kaggle account so as to use Kaggle notebooks.
- own a Google account so as to use Google Colab notebooks.
- know how to create, save, and delete files in Google Drive.
Now that you understand what machine learning is, you can begin your first project. But before you do so, let us summarize what we discussed in this article.
Conclusion
Machine learning lets you build models that learn patterns and interrelations in their sample data using specialized algorithms. A trained machine-learning model can generate insights from new data, provided the new data has the same structure as its sample data. Machine learning is divided into four categories: supervised, unsupervised, semi-supervised, and reinforcement.
The scikit-learn library has made it easy for us to implement machine-learning algorithms. So, take a break and then begin your first project.
References
Machine-learning and deep-learning books from the following publishers:
An algorithm is a set of sequential instructions. Computer applications use algorithms to accomplish specific tasks. ↩︎
Any new variables that you supply to a trained model must have the same structure as the independent variables in the sample data of the model. ↩︎
Unseen data consists of sets of independent variables that a model is unaware of. This data wasn’t part of the sample data that we used to train the model. ↩︎